 neo.js.cn@gmail.com
neo.js.cn@gmail.com
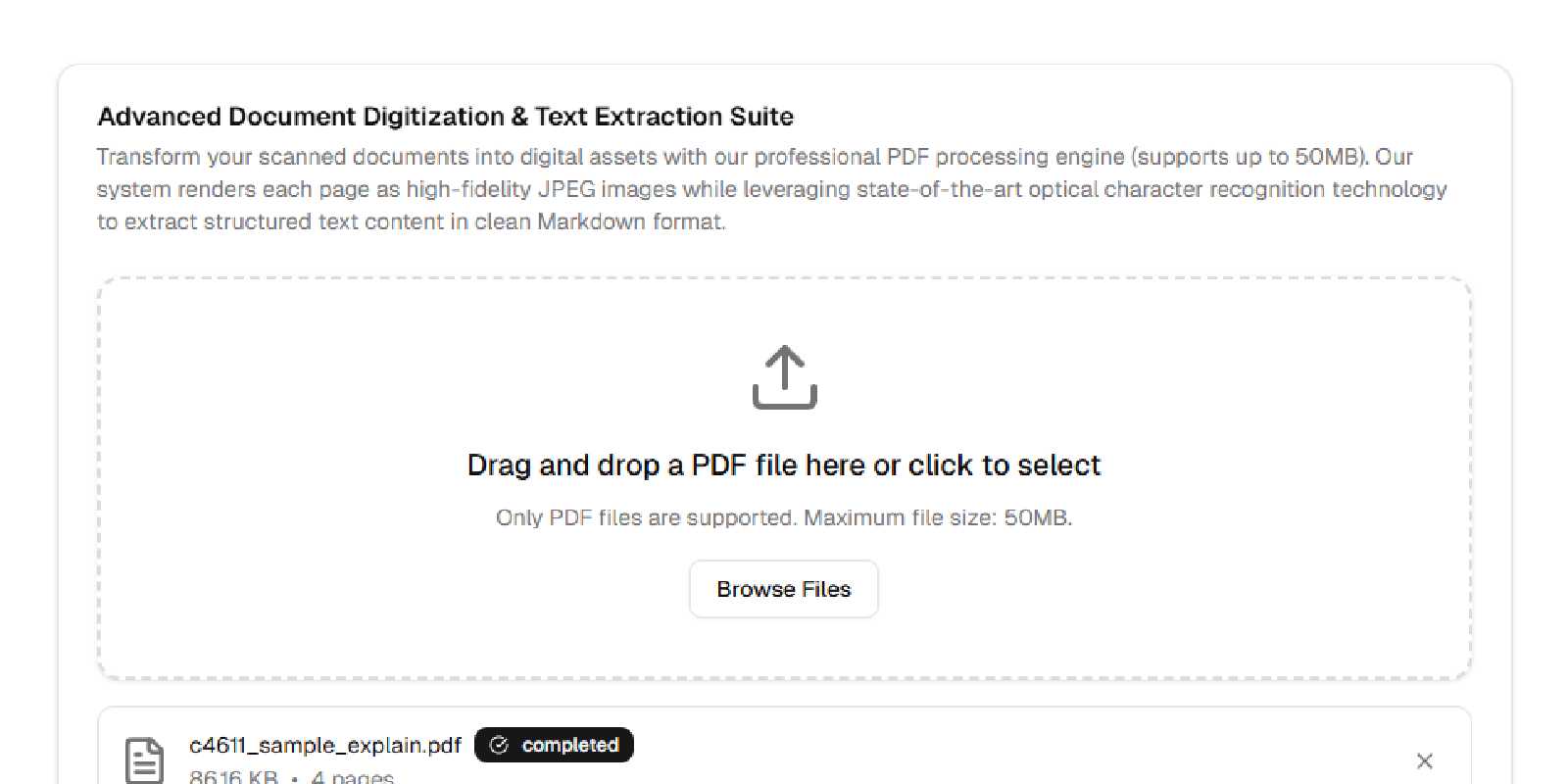
PDFxtract
PDFxtract 是一个使用 Next.js 构建的现代化 Web 应用,专门用于处理扫描的 PDF 文档。它利用先进的 OCR(光学字符识别)技术,精确地从扫描 PDF 内的图像中提取文本信息。扫描 PDF 的每一页都会被自动转换成高质量的 JPEG 图像,并通过 AI 驱动的 OCR 技术进行处理,以准确识别和提取文本内容,最后将结果输出为 Markdown 格式,方便用户使用和进一步编辑。
功能特性
- 通过简单的网页界面上传 PDF 文件
- 将每个 PDF 页面转换为高质量的 JPG 图像
- 转换后在线预览图像
- 将所有图像打包下载为 ZIP 压缩文件
- 响应式和用户友好的界面
开始使用
安装依赖:
npm install # 或 yarn install启动开发服务器:
npm run dev # 或 yarn dev打开浏览器并访问 http://localhost:3000
使用方法
- 点击主页上的上传按钮选择 PDF 文件
- 等待转换完成,图像将自动显示
- 如果需要,可将所有图像下载为 ZIP 文件
项目结构
app/ # Next.js 应用目录
api/ # PDF转JPG和创建ZIP的API路由
components/ # React 组件 (PDF上传器, UI元素等)
public/ # 静态文件和输出图像
lib/ # 工具函数
构建与部署
- 生产环境构建:
npm run build - 启动生产服务器:
npm start - 推荐部署平台: Vercel
Docker 部署
构建镜像
docker build -t pdfxtract:v0.4 .
运行容器
docker run -d -p 4012:3000 \
-e NODE_ENV=production \
-e NEXT_PUBLIC_GA_ID=<你的标签ID> \
--name pdfxtract \
pdfxtract:v0.4
Docker Compose 示例
version: '3.8'
services:
pdfxtract:
image: pdfxtract:v0.4
ports:
- "4012:3000"
environment:
- NODE_ENV=production
- NEXT_PUBLIC_GA_ID=<你的标签ID>
restart: unless-stopped
技术栈
贡献
欢迎贡献!请提交 issue 或 pull request。
